Software-Defined Assets#
A software-defined asset is a description of how to compute the contents of a particular data asset.
Relevant APIs#
| Name | Description |
|---|---|
@asset | A decorator used to define assets. |
AssetGroup | A group of software-defined assets. |
SourceAsset | A class that describes an asset, but doesn't define how to compute it. Within an AssetGroup, SourceAssets are used to represent assets that other assets depend on, but can't be materialized themselves. |
Overview#
An "asset" is an object in persistent storage, e.g. a table, a file, or a persisted machine learning model. A software-defined asset is a Dagster object that couples an asset to the function and upstream assets that are used to produce its contents. Software-defined assets enable a declarative approach to data management, in which your code is the source of truth on what data assets should exist and how those assets are computed.
A software-defined asset includes three main components:
- An
AssetKey, which is a handle for referring to the asset. - A set of upstream asset keys, which refer to assets that the contents of the software-defined asset are derived from.
- An op, which is a function responsible for computing the contents of the asset from its upstream dependencies.
A crucial distinction between software-defined assets and ops is that software-defined assets know about their dependencies, while ops do not. Ops aren't hooked up to dependencies until they're placed inside a graph.
"Materializing" an asset is the act of running its op and saving the results to persistent storage. You can initiate materializations from Dagit, Dagster's web UI, or by invoking Python APIs. By default, assets are materialized to pickle files on your local filesystem, but materialization behavior is fully customizable.
A single software-defined asset might be represented in multiple storage environments - e.g. it might have a "production" version and a "staging" version.
Defining assets#
A basic software-defined asset#
The easiest way to create a software-defined asset is with the @asset decorator.
from dagster import asset
@asset
def my_asset():
return [1, 2, 3]
By default, the name of the decorated function, my_asset, is used as the asset key. The decorated function forms the asset's op: it's responsible for producing the asset's contents. This asset doesn't depend on any other assets.
Assets with dependencies#
Software-defined assets can depend on other software-defined assets. The easiest way to define an asset dependency is to include an upstream asset name as an argument to the decorated function. In the following example, downstream_asset depends on upstream_asset. That means that the contents of upstream_asset are provided to the function that computes the contents of downstream_asset.
@asset
def upstream_asset():
return [1, 2, 3]
@asset
def downstream_asset(upstream_asset):
return upstream_asset + [4]
The explicit dependencies example covers an alternative way to specify asset dependencies without needing to match argument names to upstream asset names.
Combining assets in groups#
To materialize assets or load them in Dagit, you first need to combine them into an AssetGroup, which is a set of assets with no unsatisfied dependencies. For example:
from dagster import AssetGroup, asset
@asset
def upstream_asset():
return [1, 2, 3]
@asset
def downstream_asset(upstream_asset):
return upstream_asset + [4]
asset_group = AssetGroup([upstream_asset, downstream_asset])
To save you from needing to add each asset individually to the group, Dagster provides the AssetGroup.from_package_name method for building AssetGroups out of all the assets within all Python modules underneath a Python package:
from dagster import AssetGroup
asset_group = AssetGroup.from_package_name(
"docs_snippets.concepts.assets.package_with_assets"
)
Once assets are bundled into an asset group, you can:
- View them in Dagit.
- Materialize an ad-hoc set of them in Dagit.
- Build a job, which materializes a fixed selection of the assets in the group, and can be put on a schedule or sensor.
Viewing and materializing assets in Dagit#
Loading assets into Dagit#
To view and materialize assets in Dagit, you can point it at a module that contains an AssetGroup. E.g.
dagit -m module_with_asset_group
If you want Dagit to contain both an asset group and a set of jobs that target the assets, you can place the AssetGroup and jobs together inside a repository.
Viewing assets in Dagit#
Clicking on "Assets", in the right section of Dagit's top navigation pane, takes you to the Asset Catalog, which shows a list of all your assets.
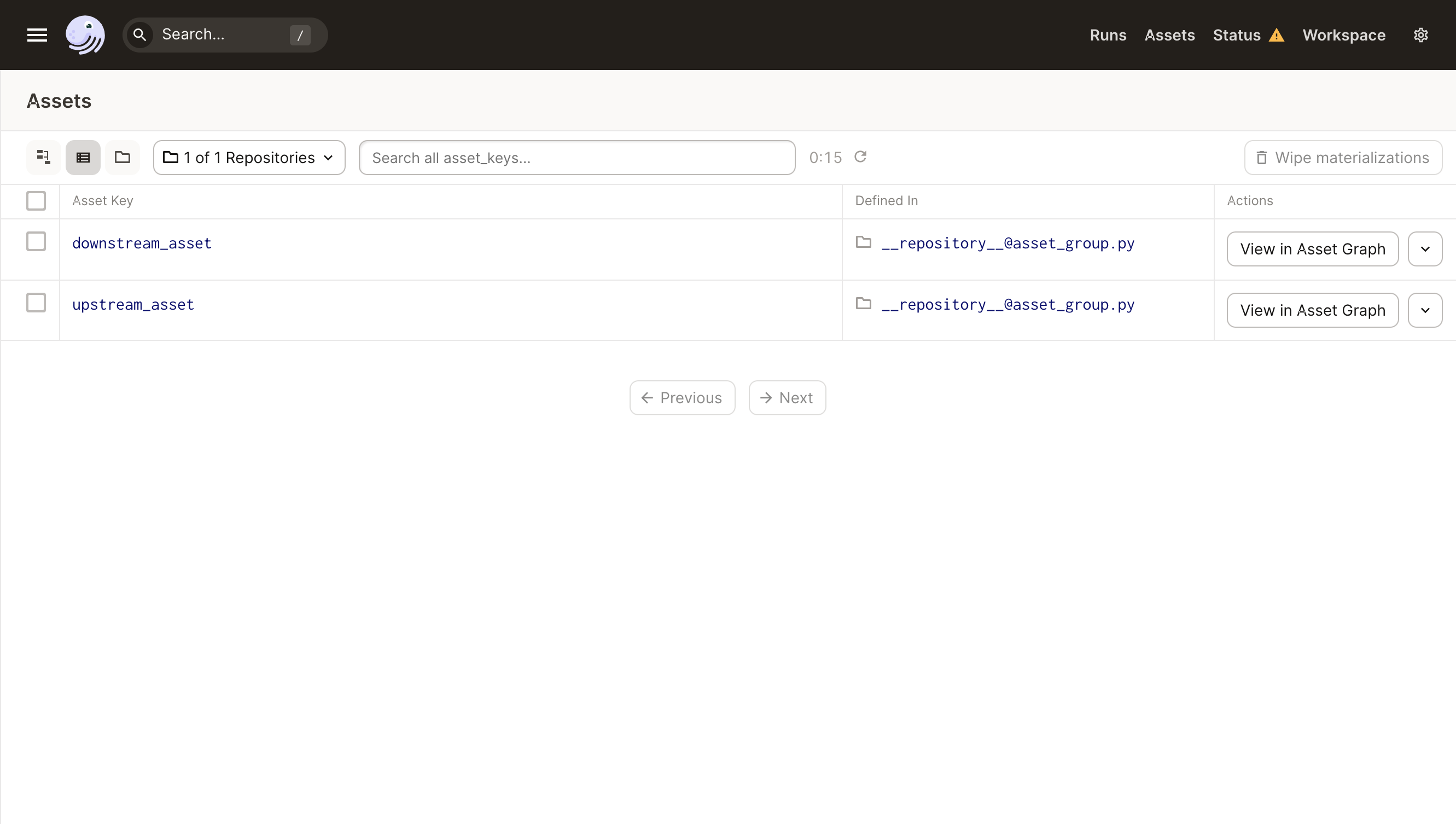
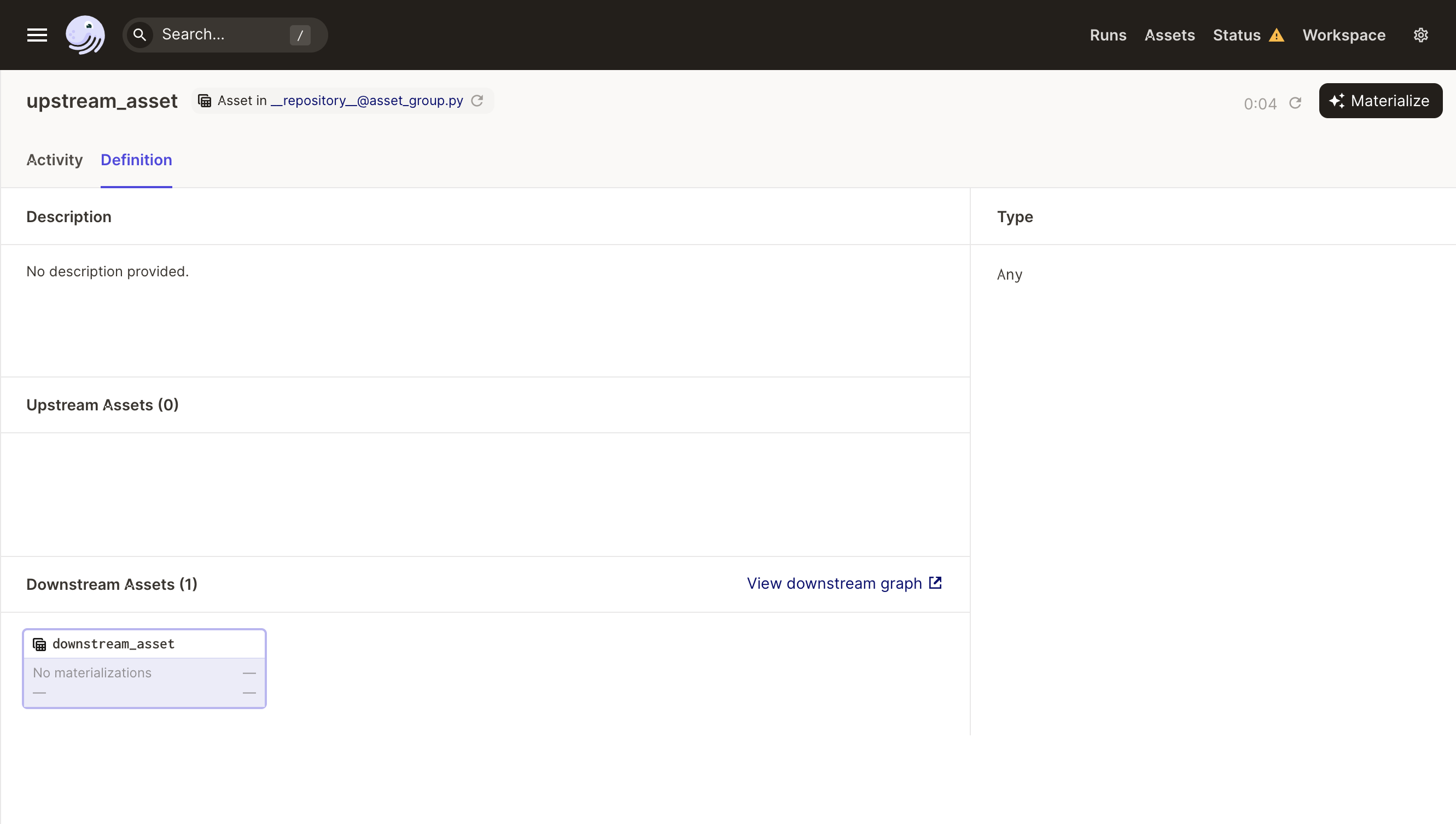
Clicking on the name of one of these assets will take you to the Asset Details Page for that asset.
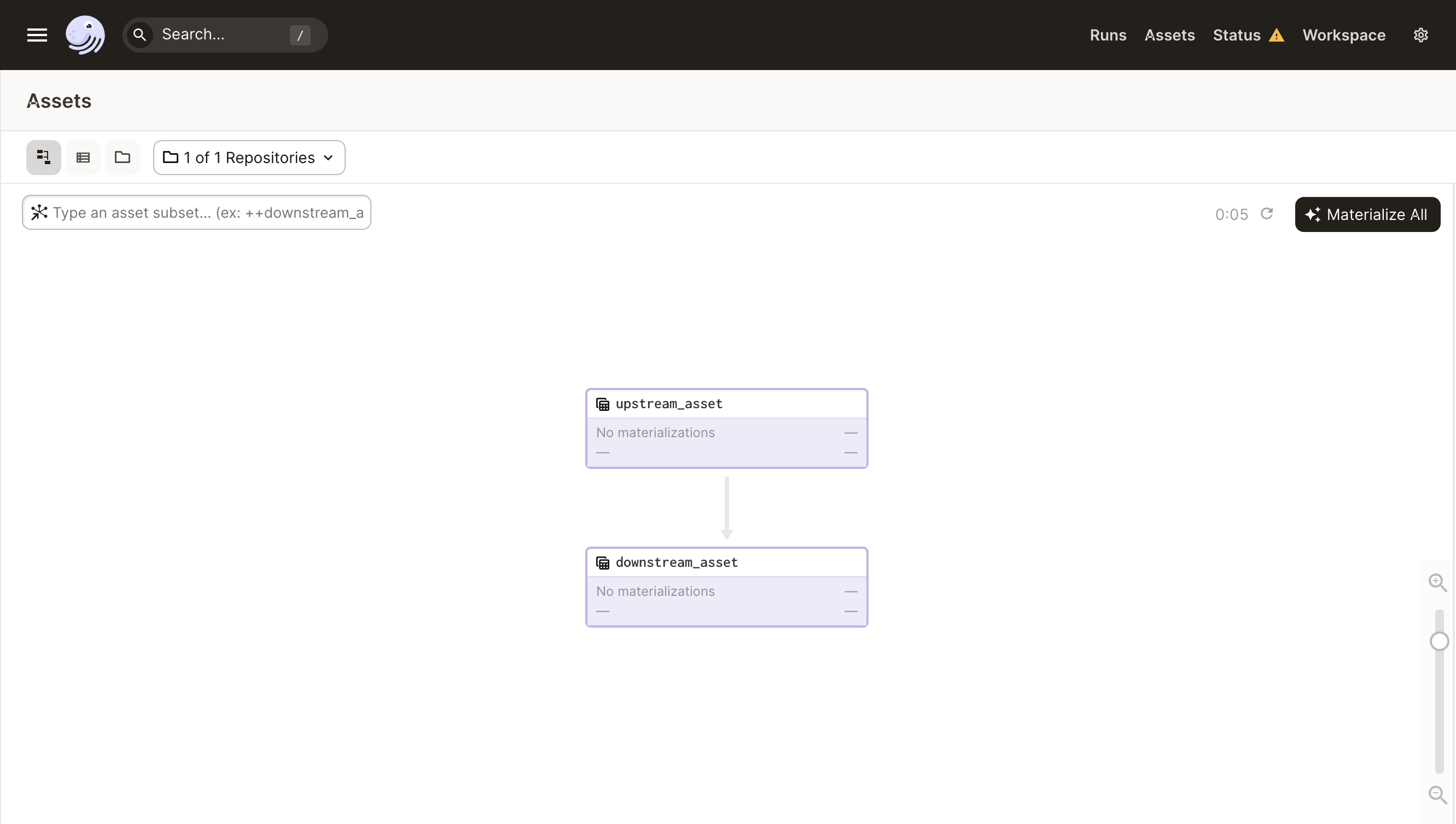
You can view a graph of all the assets with their dependencies by clicking the graph icon to the upper-left of the Asset Catalog, or by clicking "View in Graph" on any of the assets.
Materializing assets in Dagit#
There are a couple ways in Dagit to launch a run that materializes assets:
- Navigate to the Asset Details Page for the asset and click the "Materialize" button in the upper right corner.
- In the graph view of the Asset Catalog page, click the "Materialize" button in the upper right corner. You can click on assets to collect a subset to materialize.
Source assets - representing assets that are generated somewhere else#
It's common for software-defined assets to depend on assets that are generated somewhere else. For example, your data warehouse might contain a set of tables that another team is responsible for ingesting, but that your assets are derived from. To allow the assets in your AssetGroup to depend on them, you can include SourceAssets that represent them.
For example:
from dagster import AssetGroup, AssetKey, SourceAsset, asset
my_source_asset = SourceAsset(key=AssetKey("my_source_asset"))
@asset
def my_derived_asset(my_source_asset):
return my_source_asset + [4]
asset_group = AssetGroup(assets=[my_derived_asset], source_assets=[my_source_asset])
In any situation where you might use a source asset, you could also have the code inside the asset's op load the data. However, using source assets has a few advantages:
- It allows Dagit to show asset lineage that includes the source assets. If a different
AssetGroupin the same workspace contains an asset definition with the same asset key as aSourceAsset, Dagit can represent the asset lineage across those groups. - If you've already factored your data-loading code into an
IOManager, Dagster can use it to load the contents of your source asset. - It allows you to write your asset dependencies in the same way, independent of whether they're downstream from a source asset or a derived asset. This makes it easy to swap out a source asset for a derived asset and vice versa.
Customizing how assets are materialized with IO managers#
By default, materializing an asset will pickle it to a local file named "my_asset", in a temporary directory. You can specify this directory by providing a value for the local_artifact_storage property in your dagster.yaml file.
IO managers enable fully overriding this behavior and storing asset contents in any way you wish - e.g. writing them as tables in a database or as objects in a cloud object store. Dagster also provides built-in IO managers that pickle assets to AWS S3 (s3_pickle_asset_io_manager), Azure Blob Storage (adls2_pickle_asset_io_manager), and GCS (gcs_pickle_asset_io_manager), or you can write your own.
To apply an IO manager to a set of assets, you can include it with them in an AssetGroup.
from dagster_aws.s3 import s3_pickle_asset_io_manager, s3_resource
from dagster import AssetGroup, asset
@asset
def upstream_asset():
return [1, 2, 3]
@asset
def downstream_asset(upstream_asset):
return upstream_asset + [4]
asset_group = AssetGroup(
[upstream_asset, downstream_asset],
resource_defs={"io_manager": s3_pickle_asset_io_manager, "s3": s3_resource},
)
This example also includes "s3": s3_resource, because the s3_pickle_asset_io_manager depends on an s3 resource.
When upstream_asset is materialized, the value [1, 2, 3] will be will be pickled and stored in an object on S3. When downstream_asset is materialized, the value of upstream_asset will be read from S3 and depickled, and [1, 2, 3, 4] will be pickled and stored in a different object on S3.
Different assets can have different IO managers:
from dagster_aws.s3 import s3_pickle_asset_io_manager, s3_resource
from dagster import AssetGroup, asset, fs_asset_io_manager
@asset(io_manager_key="s3_io_manager")
def upstream_asset():
return [1, 2, 3]
@asset(io_manager_key="fs_io_manager")
def downstream_asset(upstream_asset):
return upstream_asset + [4]
asset_group = AssetGroup(
[upstream_asset, downstream_asset],
resource_defs={
"s3_io_manager": s3_pickle_asset_io_manager,
"s3": s3_resource,
"fs_io_manager": fs_asset_io_manager,
},
)
When upstream_asset is materialized, the value [1, 2, 3] will be will be pickled and stored in an object on S3. When downstream_asset is materialized, the value of upstream_asset will be read from S3 and depickled, and [1, 2, 3, 4] will be pickled and stored in a file on the local filesystem.
The same assets can be bound to different resources and IO managers in different environments. For example, for local development, you might want to store assets on your local filesystem while, in production, you might want to store the assets in S3.
from dagster_aws.s3 import s3_pickle_asset_io_manager, s3_resource
from dagster import AssetGroup, asset, fs_asset_io_manager
@asset
def upstream_asset():
return [1, 2, 3]
@asset
def downstream_asset(upstream_asset):
return upstream_asset + [4]
prod_asset_group = AssetGroup(
[upstream_asset, downstream_asset],
resource_defs={"io_manager": s3_pickle_asset_io_manager, "s3": s3_resource},
)
local_asset_group = AssetGroup(
[upstream_asset, downstream_asset],
resource_defs={"io_manager": fs_asset_io_manager},
)
Building jobs that materialize assets#
You can define a job that materializes a fixed selection of the assets in an AssetGroup each time it runs.
The following snippet shows examples of three different jobs you might create out of an AssetGroup.
from dagster import AssetGroup, asset
@asset
def upstream():
return [1, 2, 3]
@asset
def downstream_1(upstream):
return upstream + [4]
@asset
def downstream_2(upstream):
return len(upstream)
asset_group = AssetGroup([upstream, downstream_1, downstream_2])
all_assets = asset_group.build_job(name="my_asset_job")
downstream_assets = asset_group.build_job(
name="my_asset_job", selection=["upstream", "downstream_1"]
)
upstream_and_downstream_1 = asset_group.build_job(
name="my_asset_job", selection="*downstream_1"
)
Multiple jobs within the same repository can target overlapping sets of assets.
Like regular jobs, asset jobs can be placed on schedules and sensors.
Testing#
When writing unit tests, you can treat the function decorated by @asset as a regular python function.
Consider a simple asset with no upstream dependencies:
@asset
def my_simple_asset():
return [1, 2, 3]
When writing a unit test, you can directly invoke the decorated function.
def test_my_simple_asset():
result = my_simple_asset()
assert result == [1, 2, 3]
If you have an asset with upstream dependencies:
@asset
def more_complex_asset(my_simple_asset):
return my_simple_asset + [4, 5, 6]
You can manually provide values for those dependencies in your unit test. This allows you to test assets in isolation from one another.
def test_more_complex_asset():
result = more_complex_asset([0])
assert result == [0, 4, 5, 6]
If you use a context object in your function, @asset will provide the correct context during execution. When writing a unit test, you can mock it with build_op_context. You can use build_op_context to generate the context object because under the hood the function decorated by @asset is an op.
Consider this asset that uses a resource:
@asset
def uses_context(context):
return context.resources.foo
When writing a unit test, use build_op_context to mock the context and provide values for testing.
def test_uses_context():
context = build_op_context(resources={"foo": "bar"})
result = uses_context(context)
assert result == "bar"
Examples#
Multi-component asset keys#
Assets are often objects in systems with hierarchical namespaces, like filesystems. Because of this, it often makes sense for an asset key to be a list of strings, instead of just a single string.
from dagster import AssetIn, asset
@asset(namespace=["one", "two", "three"])
def upstream_asset():
return [1, 2, 3]
@asset(ins={"upstream_asset": AssetIn(namespace=["one", "two", "three"])})
def downstream_asset(upstream_asset):
return upstream_asset + [4]
Explicit dependencies#
If defining dependencies by matching argument names to upstream asset names feels too magical for your tastes, you can also define dependencies in a more explicit way:
from dagster import AssetIn, asset
@asset
def upstream_asset():
return [1, 2, 3]
@asset(ins={"upstream": AssetIn("upstream_asset")})
def downstream_asset(upstream):
return upstream + [4]
In this case, ins={"upstream": AssetIn("upstream_asset")} declares that the contents of the asset with the key upstream_asset will be provided to the function argument named upstream.
Using context in assets#
Since a software-defined asset contains an op, all of the typical functionality of an op (like the use of resources) is available to an asset.
@asset(required_resource_keys={"api"})
def my_asset(context):
# fetches contents of an asset
return context.resources.api.fetch_table("my_asset")
Further Reading#
Interested in learning more about software-defined assets and working through a more complex example? Check out our guide on software-defined assets and our example project that integrates software-defined assets with other Modern Data Stack tools.
See it in action#
For more examples of software-defined assets, check out the following in our SDA Hacker News example:
Our Modern Data Stack example also covers:
Our Bollinger example also covers software-defined assets