Building Graphs of Assets#
Software-defined assets can depend on other software-defined assets. An asset dependency means that the contents of an "upstream" asset are used to compute the contents of the "downstream" asset.
Why split up code into multiple assets? There are a few reasons:
- Dagster can materialize assets without re-materialize all the upstream assets. This means that, if we hit a failure, we can re-materialize just the assets that didn't materialize successfully, which often allows us to avoid re-executing expensive computation.
- When two assets don't depend on each other, Dagster can materialize them simultaneously.
Let's Get Serial#
Having defined a data set of cereals, we'll define a downstream asset that contains only the cereals that are manufactured by Nabisco.
import csv
import requests
from dagster import asset
@asset
def cereals():
response = requests.get("https://docs.dagster.io/assets/cereal.csv")
lines = response.text.split("\n")
return [row for row in csv.DictReader(lines)]
@asset
def nabisco_cereals(cereals):
"""Cereals manufactured by Nabisco"""
return [row for row in cereals if row["mfr"] == "N"]
We've defined our new asset, nabisco_cereals, with an argument, cereals.
Dagster offers a few ways of specifying asset dependencies, but the easiest is to include an upstream asset name as an argument to the decorated function. When it's time to materialize the contents of the sugariest_cereal asset, the contents of cereals asset are provided as the value for the cereals argument to its compute function.
So:
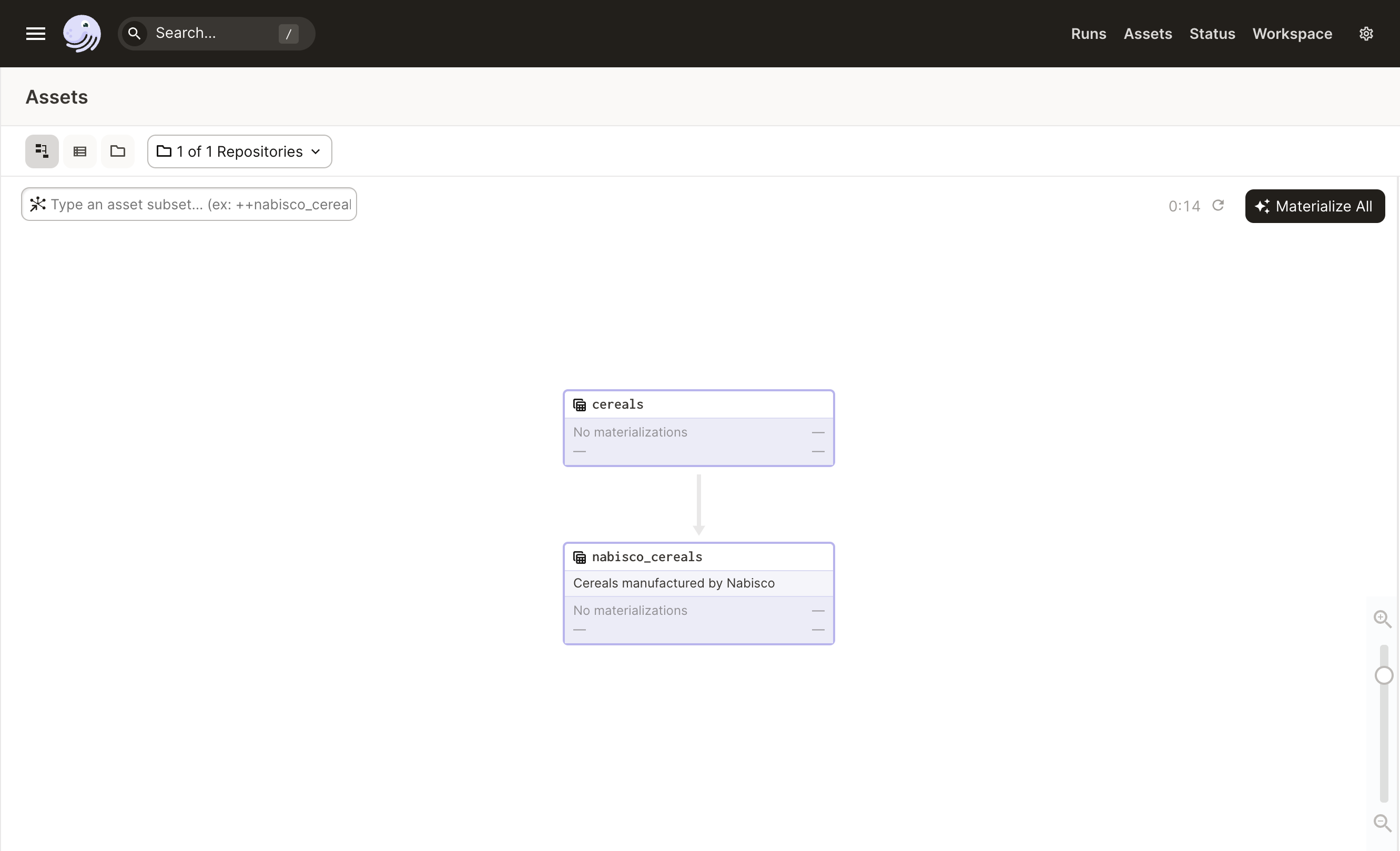
cerealsdoesn't depend on any other asset.nabisco_cerealsdependscereals.
Let's visualize these assets in Dagit:
dagit -f serial_asset_graph.py
Navigate to http://127.0.0.1:3000:
A More Complex Asset Graph#
Assets don't need to be wired together serially. An asset can be depend on and be depended on by any number of other assets.
Here, we're interested in which of Nabisco's cereals has the most protein. We define four assets:
- The
cerealsandnabisco_cerealsassets, same as above. - A
cereal_protein_fractionsasset, which records each cereal's protein content as a fraction of its total mass. - A
highest_protein_nabisco_cereal, which has is the name of the nabisco cereal that has the highest protein content.
import csv
import requests
from dagster import asset
@asset
def cereals():
response = requests.get("https://docs.dagster.io/assets/cereal.csv")
lines = response.text.split("\n")
return [row for row in csv.DictReader(lines)]
@asset
def nabisco_cereals(cereals):
"""Cereals manufactured by Nabisco"""
return [row for row in cereals if row["mfr"] == "N"]
@asset
def cereal_protein_fractions(cereals):
"""
For each cereal, records its protein content as a fraction of its total mass.
"""
result = {}
for cereal in cereals:
total_grams = float(cereal["weight"]) * 28.35
result[cereal["name"]] = float(cereal["protein"]) / total_grams
return result
@asset
def highest_protein_nabisco_cereal(nabisco_cereals, cereal_protein_fractions):
"""
The name of the nabisco cereal that has the highest protein content.
"""
sorted_by_protein = sorted(
nabisco_cereals, key=lambda cereal: cereal_protein_fractions[cereal["name"]]
)
return sorted_by_protein[-1]["name"]
Let's visualize these assets in Dagit:
dagit -f complex_asset_graph.py
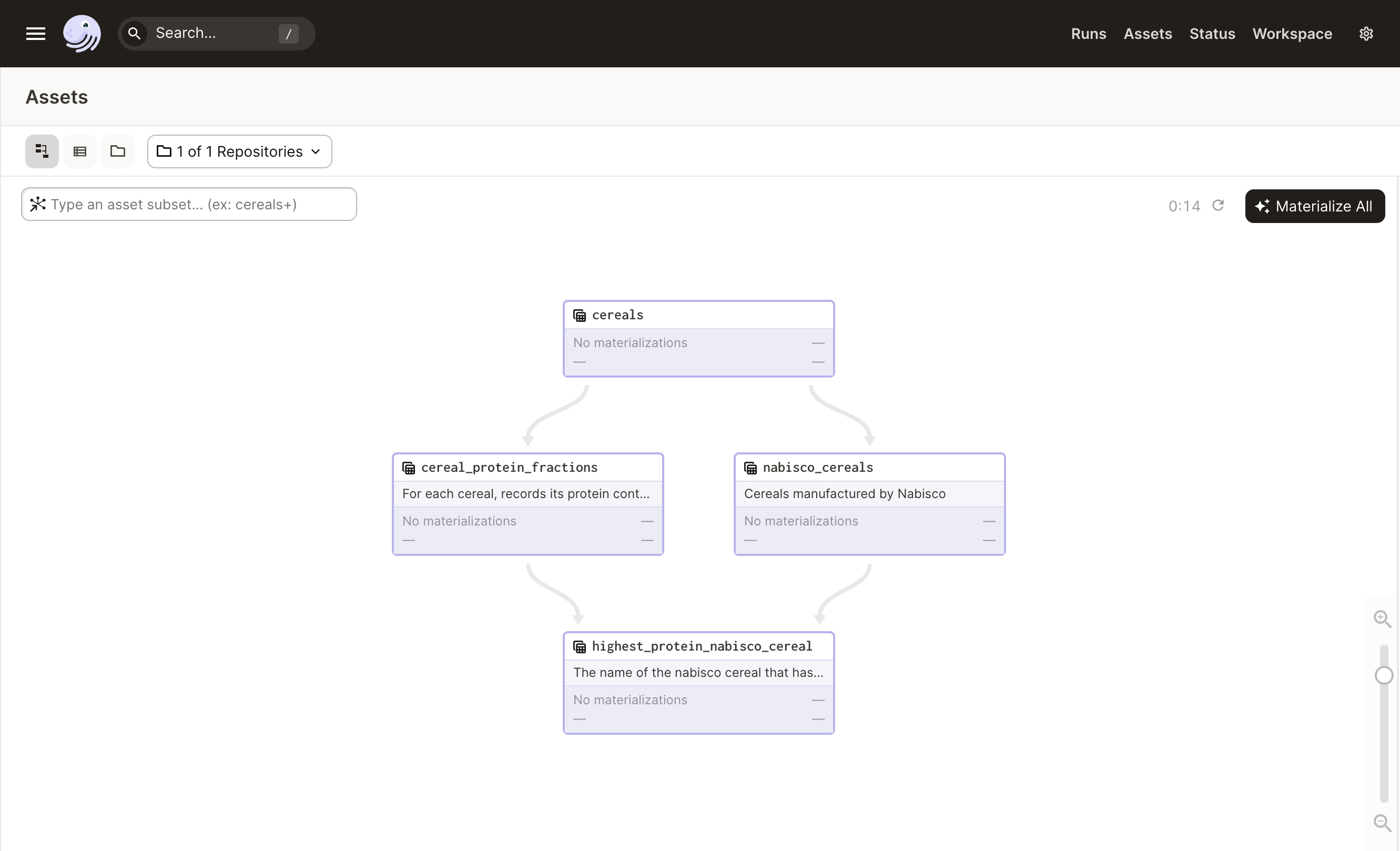
If you click the "Materialize All" button, you'll see that cereals executes first, followed by nabisco_cereals and cereal_protein_fractions executing in parallel, since they don't depend on each other's outputs. Finally, highest_protein_nabisco_cereal executes last, only after nabisco_cereals and cereal_protein_fractions have both executed.